Article
DAX : Les « clusters »
et la notion « d’auto-exist »
Rédigé par Julien Oudille – Consultant BI Actinvision
Lorsque l’on créé un visuel avec Power BI, peu importe le mode de stockage ou la complexité des calculs, la requête DAX sous-jacente aura toujours la même structure qui repose sur l’utilisation de la fonction SUMMARIZECOLUMNS.
Prenons par exemple le graphique ci-dessous avec un filtre basique :
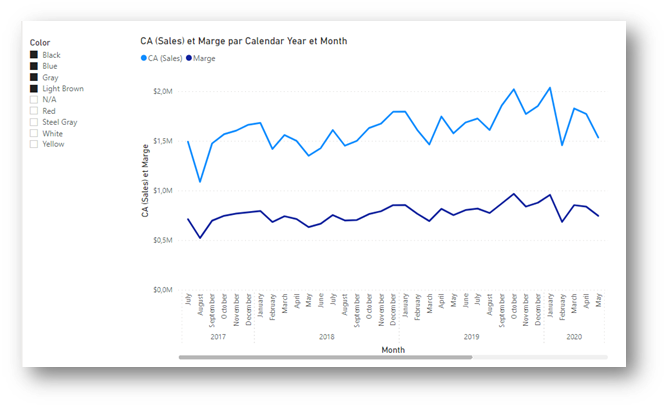
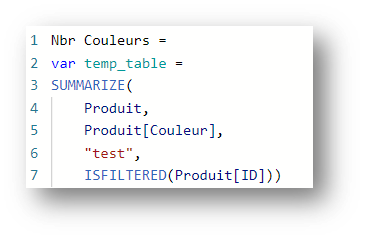
La requête DAX envoyée et exécutée par le moteur est la suivante :
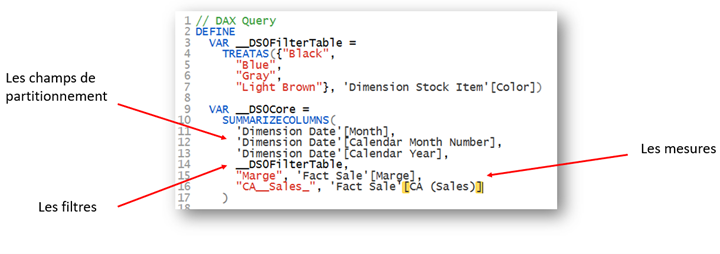
La fonction SUMMARIZECOLUMNS possède 3 types d’arguments : les champs de partitionnement (les axes du visuel), les filtres (arguments de tables) et les mesures.
Dans cet article, nous allons voir de quelle manière Power BI interprète un système de filtres composé de plusieurs colonnes de la même table.
CAS D’ETUDE :
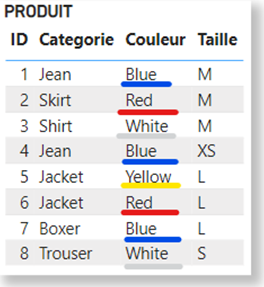
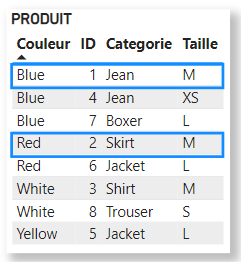
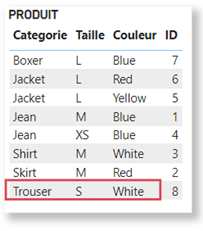
Considérons la table PRODUIT suivante dans le cadre de cette démonstration :
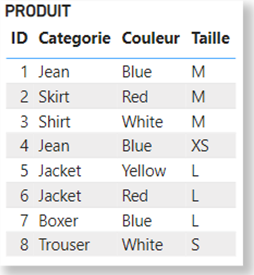
Dès lors qu’une table est appelée dans une expression DAX, Power BI crée ce qu’on appelle un cluster de données, qui correspond à l’ensemble des combinaisons de valeurs effectivement présentes dans la table.
Un exemple avec la mesure suivante pour calculer le nombre de couleurs distinctes :
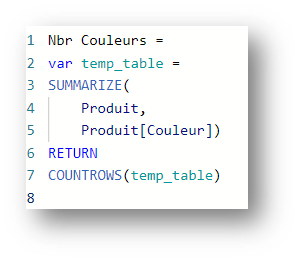
Cette requête nous retourne évidemment le nombre 4.
Faisons un test en rajoutant un compteur du nombre de lignes au global dans la table temp_table.
En supposant que le seul filtre posé ici est sur le champ Produit[Couleur], il suffirait d’ajouter l’expression suivante :
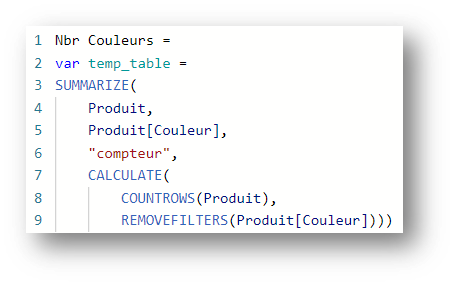
Un MAX sur cette table devrait donc toujours nous donner 8, or l’expression suivante nous donne le résultat 3 :
Ceci est lié au comportement de la fonction SUMMARIZE, qui introduit systématiquement un cluster de données selon la table appelée.
Pour chaque combinaison de valeurs des colonnes appelées, Power BI va également placer des filtres sur toutes les colonnes de la table appelée, en fonction des combinaisons de valeurs présentes dans la table.
La table Produit, ici groupée par Couleur, contient les clusters suivants pour chaque couleur :
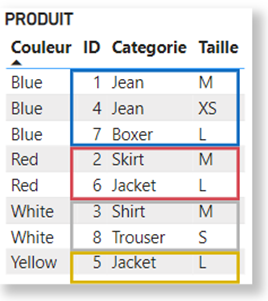
Autrement dit, pour la couleur Blue, Power BI introduit le filtre suivant :
(ID = 1 and Categorie = “Jean” and Taille = “M”)
OR
(ID = 4 and Categorie = “Jean” and Taille = “XS”)
OR
(ID = 7 and Categorie = “Boxer” and Taille = “L”)
C’est pourquoi en enlevant le filtre sur Produit[Couleur] dans notre mesure, on obtient seulement 3, à savoir les 3 lignes ci-dessus.
On peut introduire un test dans l’expression pour vérifier s’il y a bien un filtre direct appliqué sur la colonne Produit[ID] par exemple :
Le résultat est systématiquement TRUE.
Prenons un autre exemple, avec une expression de filtre sur les champs Couleur et Taille :
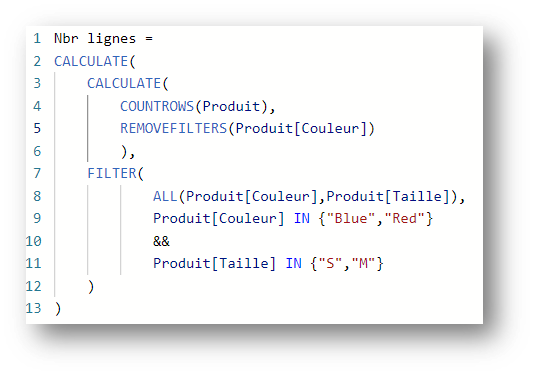
Cette expression nous retourne 2, à savoir les 2 lignes suivantes :
Nous avons à nouveau un filtre qui implique 2 colonnes de la même table. Ce principe de « clustering » s’applique à nouveau, et le FILTER retourne une table qui contient les combinaisons de valeurs distinctes des colonnes Produit[Couleur] et Produit[Taille] en fonction du filtre appliqué.
Ici, les clusters sont donc les suivants : {Blue,M},{Red,M}
La valeur « S » n’est pas retournée car il n’existe aucune ligne de données {Blue,S} ou {Red,S}.
C’est la notion d’auto-exist : en créant ses clsuters, Power BI ne retourne que les combinaisons de données effectivement présentes dans la table cible.
Ainsi, l’expression suivante ne donne pas 4 comme on pourrait s’y attendre (les 4 lignes avec soit « M » soit « S »), mais bien 3 :
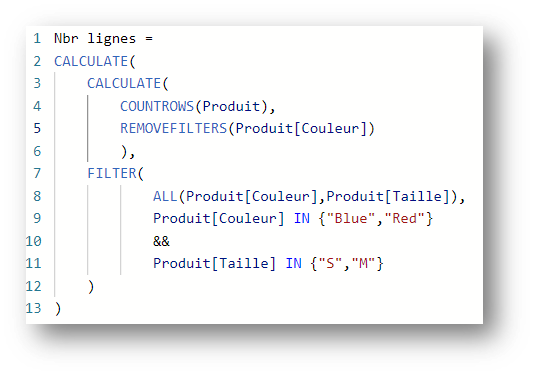

Toute fonction DAX qui retourne une table introduit des clusters de valeurs qui s’appuient sur la notion d’auto-exist.
Ce comportement est le même lorsque le système de filtre est induit par des visuels, par le biais de la fonction SUMMARIZECOLUMNS qui va créer les clusters lorsque les colonnes filtrées proviennent d’une seule et même table.
Prenons cette fois la mesure suivante :
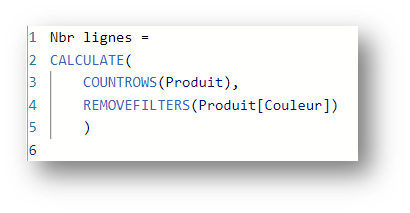
Si on configure les mêmes filtres sur les colonnes Couleur et Taille, on obtiendra exactement le même résultat, au lieu des 4 lignes attendues pour les tailles « M » et « S » :
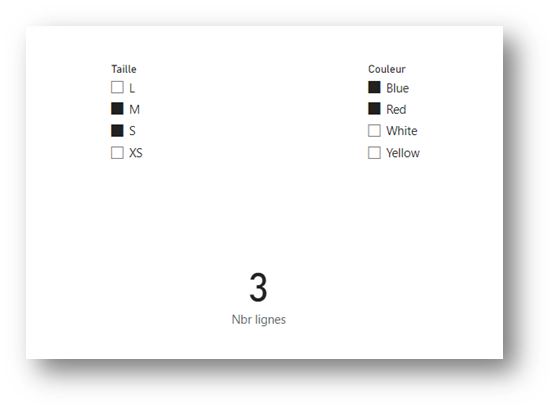
Pour aller plus loin dans l’analyse, lorsqu’un cluster est introduit avec un système de colonnes et que les valeurs d’une de ces colonnes sont remplacées ultérieurement par une autre expression, elles sont remplacées à l’intérieur du cluster préalablement introduit.
Considérons la mesure suivante :
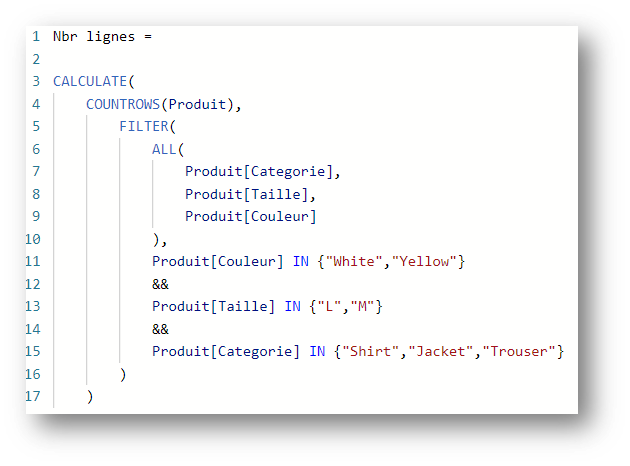
On introduit ici le cluster de valeurs suivantes sur les colonnes Categorie, Taille et Couleur :
{Jacket,L,Yellow}, {Shirt,M,White}. La mesure retourne donc 2.
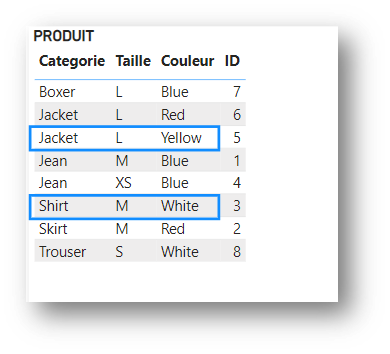

Effectuons une petite modification dans le calcul :
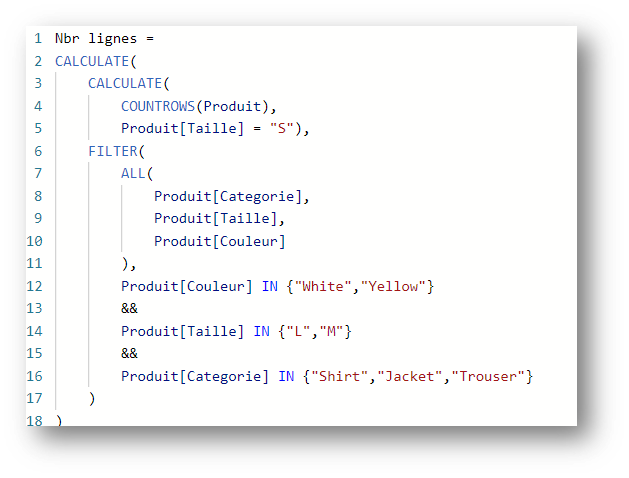
En appliquant le filtre Produit[Taille] = S dans le calcul de manière ultérieure, on peut s’attendre à remplacer le précédent cluster par le cluster suivant :
{Trouser,S,White}
Il n’en est rien. Car seul le champ Produit[Taille] est impacté par ce nouveau filtre.
Power BI va transformer les filtres appliqués de la manière suivante :
{Jacket,L,Yellow}, {Shirt,M,White} à ({Jacket,Yellow}, {Shirt,White}) && {S}
Au lieu de retourner la ligne {Trouser,S,White}, cette mesure retourne donc un (vide), car il n’y a aucune ligne correspondante.

En conclusion lorsqu’une fonction DAX retourne une table ou lorsque plusieurs champs d’une même table sont filtrés, Power BI introduit un cluster de valeurs pour les colonnes filtrés, qui contient les combinaisons de valeurs distinctes présentes dans la table.
Lors de l’évaluation d’un visuel, Power BI introduit systématiquement une fonction SUMMARIZECOLUMNS.
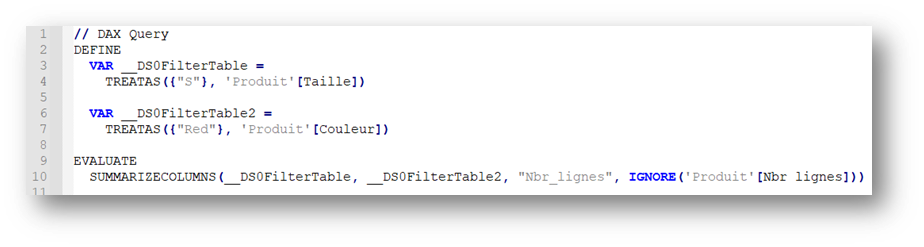
L’auto-exist s’applique alors sur les colonnes qui proviennent d’une seule et même table, de la même manière qu’avec une table appelée en argument de filtre d’un CALCULATE ou d’un CALCULATETABLE.
Cette notion d’auto-exist permet d’améliorer la vitesse de traitement mais peut conduire à des résultats erronés lors de l’utilisation de fonction de contexte, comme REMOVEFILTER().
C’est une des raisons pour lesquelles il faut privilégier une modélisation en étoiles sur Power BI.





