Article
Maximiser la fiabilité des données géographiques avec Snowpark
Retour d’expérience Shippeo
Comment Shippeo, un des leaders mondiaux et spécialiste européen de la visibilité du transport en temps réel, assure la qualité de ses données géographiques grâce à Snowpark for Python ?
Simon Keith, Staff Engineer Shippeo, revient sur leur utilisation des algorithmes de Machine Learning pour réaliser des traitements de détection d’anomalies liés au géocodage, et comment Shippeo a réussi à se démarquer en gagnant en temps et coût de traitement.
Shippeo
Shippeo, l’un des leaders mondiaux et expert européen en matière de suivi en temps réel des transports, collabore avec les principaux expéditeurs et prestataires logistiques pour garantir une qualité de service et procurer un suivi tout le long de la Supply Chain dans le domaine du transport.
Dans la même optique que le B2C avec la visibilité en temps réel des livraisons de colis ou des applications VTC, la solution RTTV (Real Time Transport Visibility) de Shippeo offre le même niveau d’expérience en termes de visibilité à ses clients B2B. En se connectant aux systèmes télématiques des transporteurs, l’information est agrégée et restituée de manière intelligible aux utilisateurs.

Snowpark for Python
Snowpark est une API introduite par Snowflake en 2021, élargissant son support pour Python à partir de juin 2022. Cette interface offre la possibilité d’exécuter du code Python, Java et Scala directement dans l’environnement Snowflake, ouvrant ainsi la porte à une flexibilité accrue dans le traitement des données. Grâce à Snowpark for Python, les utilisateurs peuvent manipuler les données en base à l’aide de dataframes Snowflake, simplifiant ainsi les opérations de traitement. L’accès à un vaste éventail de bibliothèques utiles renforce davantage la puissance de cette API, offrant aux développeurs une panoplie d’outils pour optimiser leurs flux de travail et profiter de la performance et la scalabilité de l’écosystème Snowflake.
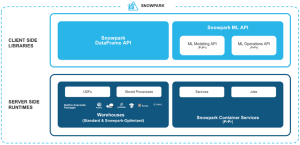
Source : Snowflake
Cas d’usage et solution proposée
Afin de transformer les adresses que fournissent les donneurs d’ordre à Shippeo en coordonnées GPS utilisables par leurs systèmes, une API de geocodage est utilisée. Le géocodage n’est pas infaillible, et il arrive qu’il se trompe de quelques centaines de mètre voire plusieurs kilomètres. Les raisons peuvent être des erreurs humaines, des détails d’adresse incomplets, plusieurs emplacements correspondant aux mêmes détails d’adresses, etc.
Une approche en deux étapes a donc été suggérée aux équipes de Shippeo, la première en détectant d’abord les emplacements incorrects en SQL, la seconde en suggérant des zones qui peuvent correspondre aux véritables détails d’adresse en utilisant le regroupement par clustering en Python.
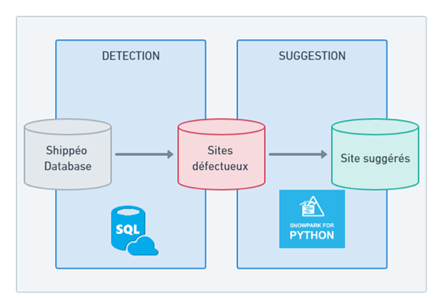
Schéma de la solution proposée
Résultat de la mise en production
Avant
Le processus en place chez Shippeo présentait des défis significatifs en termes de temps d’exécution, nécessitant environ 4 heures de traitement, et sa complexité rendait difficile une réexécution en cas de problème. En ce qui concerne la scalabilité et la fiabilité, il était impossible de modifier facilement les ressources allouées au flux, ce qui pouvait entraîner des conflits avec d’autres traitements concurrents. Les coûts associés à cette approche étaient donc difficiles à prévoir et à surveiller, nécessitant un scale-up de la base PostgreSQL pour maintenir les performances. De plus, la gouvernance des données était compromise par le déplacement fréquent des données entre plusieurs systèmes, créant des défis supplémentaires en matière de gestion et de sécurité.
Après
Depuis le déploiement de Snowpark for Python, les performances ont considérablement augmenté avec un temps d’exécution réduit à 15 minutes, une reproductibilité facile et une stabilité opérationnelle. La scalabilité est optimale grâce à la possibilité de redimensionner le warehouse selon les besoins et les coûts, assurant une exécution fiable avec peu d’incidents. Les coûts restent entre 15 et 20 euros par mois, avec une surveillance et une ajustabilité continues. Cette solution libère des ressources dans la base source et sépare le stockage du calcul. En termes de gouvernance, les données sont traitées intégralement sur Snowflake, profitant ainsi de sa robustesse et de sa conformité intégrées.





