Comment Alteryx permet d’intégrer des données PDF / images
Article rédigé par Marie Nadia Uwurukundo – Consultante BI Actinvision
Alteryx, leader dans le domaine de la préparation et l’analyse de données, permet aux utilisateurs de transformer rapidement des données brutes en informations exploitables, sans nécessiter de compétences avancées en programmation ou en science des données. Dès 2020, Alteryx met à disposition de ses utilisateurs trois palettes d’outils basées sur l’intelligence artificielle : machine learning, exploration du texte et vision par ordinateur. C’est l’Intelligence Suite Alteryx.
Cet article présente comment Alteryx, à l’aide des outils « vision par ordinateur », facilite la conversion des images ou de documents numérisés en data exploitables.
Quels cas d’usages pour l’OCR ?
Aujourd’hui, de nombreuses entreprises sont confrontées à la gestion de documents numérisés au format PDF ou image. Ils recherchent ainsi des solutions efficaces pour extraire des informations à partir de ces documents, ou même les classifier. La technologie OCR, Optical Character Recognition ou Reconnaissance Optique de Caractères, permet aux utilisateurs d’extraire des données à partir d’images et documents numériques. Parmi certains cas d’usage, on peut citer : l’extraction des données sur les factures, l’analyse de documents, le traitement des formulaires, etc.
Pour exemple, une entreprise fait face à une pile de factures de différents fournisseurs. En utilisant les outils OCR, cette entreprise peut extraire automatiquement les informations clés telles que les montants, les dates et les détails de fournisseurs à partir des factures numérisées.

Qu’est ce qui était proposé jusqu’à présent ?
Les personnes confrontées à de l’ingestion de factures dans des systèmes d’information peuvent être contraints de saisir manuellement des fichiers texte. Cet effort, désuet, chronophage et sans valeur ajoutée, est souvent source d’erreurs humaines. Des membres de la communauté Alteryx ont déjà pu proposer des macros, basées sur les langages de programmation, R ou Python pour pallier ce problème. Cependant, ces outils de développement s’avèrent régulièrement difficiles à mettre en place dans un environnement de production et d’automatisation.
Le plus souvent, sur Alteryx, la solution envisagée consistait à lire le fichier PDF comme un fichier texte avec l’outil « PDF vers texte ». Ainsi, les données, si elles étaient lisibles et complètes, devaient être retravaillées dans un workflow complexe et long en étapes pour un résultat convenable.
Les forces de l’Intelligence Suite Alteryx
En 2021, Alteryx intègre les outils OCR à son Intelligence Suite. La valeur ajoutée de l’outil est de donner la possibilité à des milliers d’utilisateurs d’exploiter la reconnaissance d’images sans une ligne de code. A travers son interface conviviale et intuitive, Alteryx rend accessible à tous types d’utilisateurs cette technologie auparavant réservée aux Data Scientist ou Data Engineer.
L’utilisateur peut maintenant ajouter ces nouvelles briques OCR à son workflow, toujours de manière ludique comme construire différents blocs de Lego.

Comment marche OCR sur l’Intelligence Suite Alteryx ?
La licence Intelligence Suite Alteryx met à disposition ses outils OCR mais aussi les outils de Machine Learning assisté, ainsi que d’exploration de texte. Deux outils sont ensuite nécessaires. L’utilisateur glisse et dépose en premier l’outil « Entrée d’image/PDF » dans son workflow pour chercher une image ou un répertoire d’image à traiter. Il insère à la suite l’outil « Image en texte » ou « PDF en texte », pour indiquer qu’il souhaite extraire les informations texte des fichiers en entrée. La configuration permet ensuite d’utiliser un template ou non, pour aider les algorithmes d’extraction des données. Ce choix dépend de la structure des documents.
Avec template
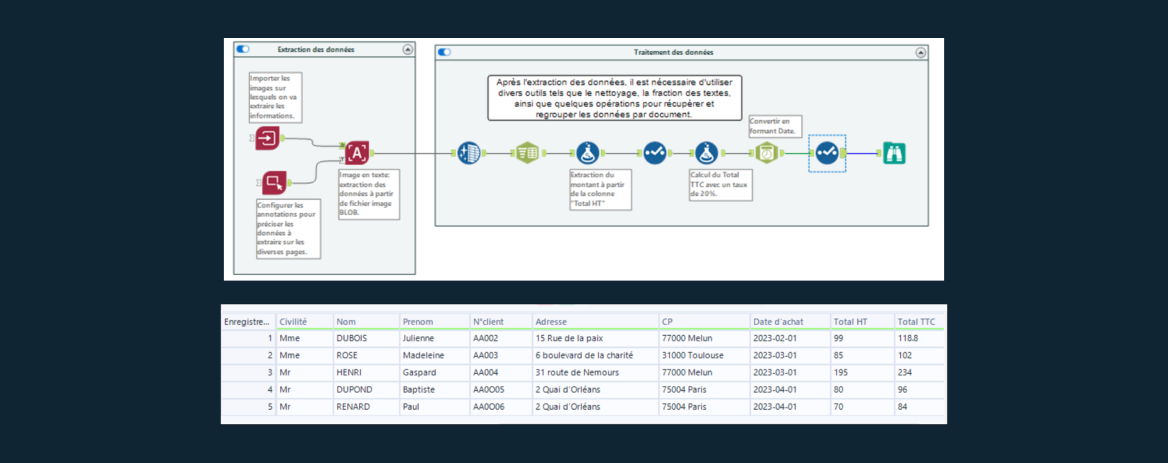
Si les documents ou les images présentent la même structure, il est préférable d’utiliser le template car cela permet une extraction plus rapide de données. Les informations situées à des emplacements différents de l’image sont automatiquement placées dans des colonnes dédiées. La donnée est alors prête à être utilisée et ne nécessite pas de retraitement. Bien entendu, cette fonction perd en efficacité si les encarts de texte changent d’emplacement. Les informations sont alors ignorées. C’est pourquoi il est nécessaire parfois de ne pas utiliser le template.
Sans template
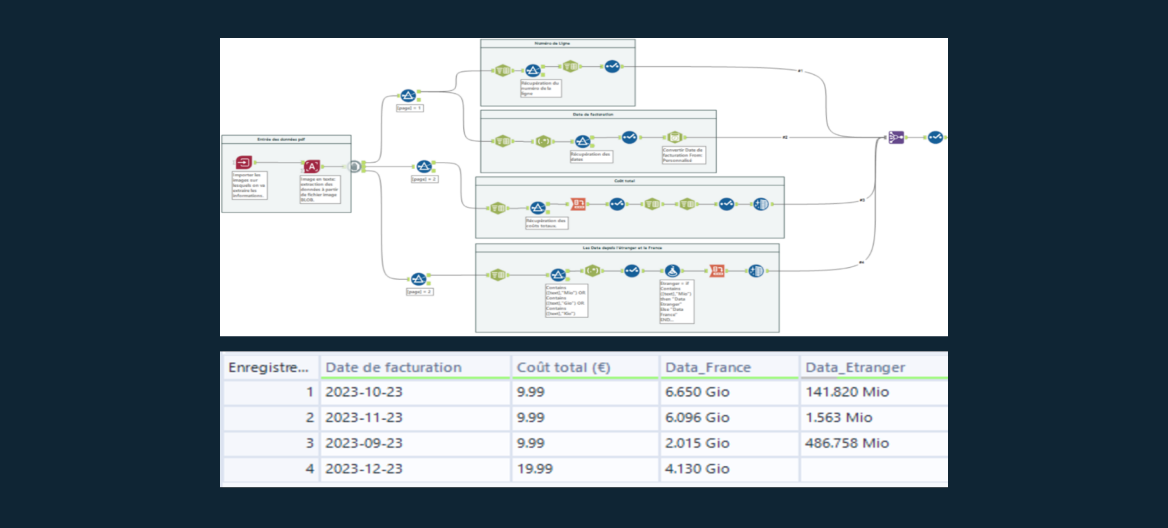
Sans le template, le processus est plus long et complexe mais garantit une extraction exhaustive des informations. Toutes les données sont récupérées et combinées dans une seule colonne de sortie. L’utilisateur doit alors retraiter l’intégralité de la colonne pour isoler les informations voulues. Cette seconde manière mobilise des connaissances plus avancées des outils parsing Alteryx comme pour l’utilisation de l’outil « PDF en texte ».
Quelles autres possibilités offrent les outils OCR Alteryx ?
Ces outils OCR d’extraction de texte ouvrent la voie à une récupération aisée des données contenues dans des images et documents PDF. Dans la même suite d’outils, Alteryx intègre un outil « Reconnaissance d’image ». Celui-ci permet de réaliser une classification automatisée des images.
Ces outils sont complémentaires au sein des projets d’intégration de données PDF/Image. En effet, il est possible d’utiliser la « Reconnaissance d’image » pour classer et identifier les documents. Ensuite, en fonction du document, l’outil « Image vers Texte » ou « PDF en texte » permettent de récupérer les informations disponibles et de les intégrer dans une base de données cible.
Vous souhaitez réaliser un projet de récupération automatique de vos informations provenant de PDF ou d’images, contactez-nous.





