Article Matillion
Comment se servir de
Matillion pour exploiter
les données de la Formule 1 ?
Rédigé par Nadia Meddeb – Consultante BI Actinvision
Introduction
Matillion est un outil de traitement de données permettant de récupérer, préparer et transformer les données, en ayant recourt à la méthode ELT : (Extract, Load and Transform). Comme nous pouvons le constater, l’ELT consiste à extraire les données depuis plusieurs sources existantes, et de les charger dans un entrepôt de données avant de procéder aux différentes transformations. Dans notre cas de figure, nous allons utiliser cet outil lors d’une démonstration. Le but étant de mettre en place une solution d’intégration de données, en utilisant les différentes fonctionnalités que Matillion offre. Ayant récemment découvert l’univers de la Formule 1 à travers la fameuse série Netflix « Drive to survive », j’ai décidé de me plonger davantage dans ce monde fascinant, et de bâtir mon propre scénario de démonstration sur ce sujet. Cette démonstration va nous permettre de combiner la puissance de l’outil Matillion, ainsi que les données liées à la Formule 1.
A la quête des données
La première étape consiste à trouver le socle de notre projet : les données. Durant notre démonstration, nous allons utiliser les données des 3 dernières saisons de la Formule 1, car elles sont représentatives et fiables.
Les données choisies sont des données semi-structurées, accessibles sous différents formats, ce qui va nous permettre d’exploiter toute la force de Matillion grâce à la diversité des connecteurs disponibles.
Matillion s’avère être un excellent choix, pour traiter des données extraites des différentes sources que j’ai pu trouver gratuitement sur internet (fichiers CSV/EXCEL, API). Ces sources vont nous permettre de charger ces données dans un entrepôt de données.

Comment charger ces données ?
Une fois notre jeu de données prêt, nous pouvons commencer le chargement. Matillion propose une multitude d’actions de manipulation de données, qui sont scindées en deux catégories : l’orchestration et la transformation.
A ce stade, nous allons utiliser les jobs d’orchestration qui concernent l’extraction, la connexion aux sources, la création des tables (sous Snowflake), le chargement, ainsi que l’orchestration des différents traitements réalisés.
Notre jeu de données se compose de plusieurs parties :
Les résultats des courses de chaque circuit lors d’une saison qui fera office de source
La liste des conducteurs présents lors des 3 dernières saisons
La liste des différents constructeurs
La liste de tous les circuits depuis le début de la Formule 1
Que ce soient des fichiers plats ou encore des xml résultant d’un appel d’API, les jobs d’orchestration vont nous permettre de tout charger.
Données disponibles, transformations accessibles
Une fois nos données chargées, nous pouvons procéder aux différentes transformations. Cette étape nous permet de mieux structurer nos données, pour pouvoir atteindre notre objectif final, qui est de mettre en place une solution d’intégration de données.
L’utilisation de Matillion est très simple. Grâce à son interface très visuelle des projets, le challenge devient beaucoup plus accessible. Les jobs de transformation concernent principalement la lecture des données à traiter, les jointures entres les différentes tables, les calculs à réaliser, et l’écriture de données. Tout ceci va nous permettre de manipuler facilement nos données.
Pour notre cas de figure, le but est de pouvoir exploiter nos données pour en tirer des informations. Lors de notre phase de transformation, nous commençons par créer nos dimensions, qui contiennent nos axes d’analyse, à partir desquels on veut étudier des données observables dans notre table de fait.
Notre table de fait contient principalement les résultats des courses (rang, statut, nombre de tours, vitesse moyenne etc.). C’est pourquoi nous allons créer les dimensions suivantes :
Statut : contient les différents statuts d’une course
Conducteurs : contient les informations relatives aux conducteurs (identité, nationalité, team, nombres de courses gagnées/championnat gagnés).
Constructeur : contient les informations relatives aux constructeurs (Nom, fondateur, chef, chef technique, année d’entrée dans la Formule 1 etc.)
Circuit : contient les informations relatives aux circuits des courses (Ville, longitude, latitude, longueur du circuit etc.)
Les jobs de transformation nous ont permis de créer nos dimensions, de nettoyer nos données, de créer une historisation dans les différentes dimensions pour une traçabilité continue, mais aussi l’alimentation de notre table des faits.
(Exemple de transformations ci-dessous)
![]()
Différents outils ressemblent à l’outil Matillion dans l’utilisation (Talend, Informatica, Azure). Que ce soit sur le concept drag and drop de composants, afin de manipuler les données, la connexion dans un ordre logique des composants, afin d’effectuer les traitements ou encore la disponibilité de nombreuses fonctions et de librairies, tous se basent sur la même logique.
C’est pourquoi la prise en main de l’outil est très facile si on a déjà travaillé sur un outil similaire. Même pour les novices, grâce à une documentation riche , la compréhension de l’outil est assez simple et rapide.
L’outil dispose d’une visualisation claire, ce qui permet une organisation limpide des jobs d’orchestration et de transformation que l’on souhaite créer.
Grace à une interface graphique « User-friendly », nous avons une réelle idée du flux de données de notre projet (figure ci-dessous).
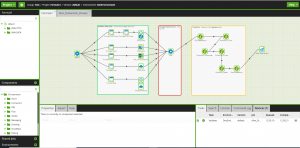
Conclusion
Matillion est un outil cloud de traitement de données, qui présente plusieurs avantages par rapport à ses concurrents. Il permet un gain de temps en développement grâce à sa multitude de sources, une transmission de connaissance simple, et un bénéfice de la puissance de calculs des solutions d’entrepôt de données disponibles et de leurs avantages. Il s’est avéré être un choix efficace pour mon projet.





