Snowflake lance Data Lake Export
Snowflake, le créateur du data cloud, annonce le lancement en preview publique de la fonctionnalité Data Lake Export. Cette dernière rend les données de Snowflake plus accessibles aux data lakes externes et permet aux clients de profiter des capacités de traitement fiables et performantes de Snowflake.
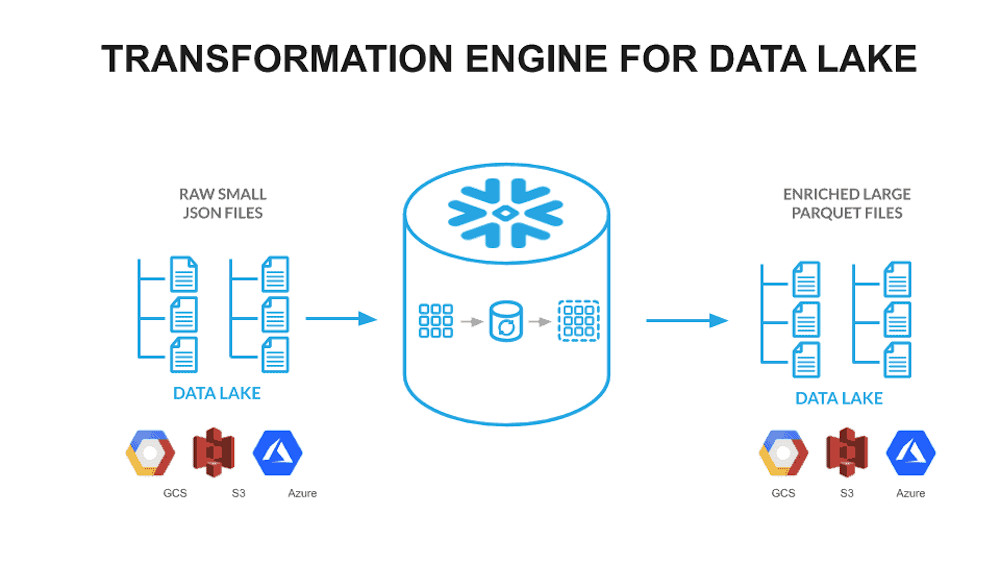
Data Lake export est notamment utile pour les entreprises qui utilisent Snowflake afin d’enrichir un data lake existant. Grâce à cette fonctionnalité, les données brutes provenant de diverses sources peuvent être converties en fichiers Apaches Parquet, et ensuite utilisées pour construire des tableaux et des vues pour les consommateurs de données.
Snowflake Data Lake Export permet également d’optimiser la taille des fichiers. Les petits fichiers sur les data lakes entraînent des requêtes extrêmement inefficaces. Pour des performances plus rapides, il est important de compacter les ensembles de données en fichiers parquet de grande taille et très réduits. Lorsque max_file_size est utilisé dans une tâche d’exportation de data lake, Snowflake tente de créer des fichiers parquet aussi proches que possible de la taille de fichier fournie.
Enfin, Snowflake inclut les ID de requête dans les noms de fichiers. Cela permet aux clients d’identifier facilement tous les fichiers qui ont été créés à l’aide d’une tâche particulière, ce qui améliorera la cohérence des données dans le data lake.
De nombreux clients ont participé à la preview privée de Data Lake Export et ont mis en place des pipelines de bout en bout comme décrits dans l’image ci-dessous. Ce pipeline convertit les données brutes JSON ou CSV en fichiers parquet, en utilisant Snowflake pour un traitement performant avec des fonctionnalités telles que les tables externes, les flux de tables, les tâches et l’exportation du data lake.





