Article
Snowpipe :
Service d’ingestion automatique de fichiers dans le cloud
Rédigé par Rudy Krauffel – Consultant BI Actinvision
Rendu public en décembre 2017, Snowpipe est un service Snowflake de chargement de données continu, rapide à mettre en place et à la tarification avantageuse. S’appuyant sur le stockage de fichiers dans le cloud des principaux acteurs (Microsoft Azure, Amazon Web Services et Google Cloud Storage) ainsi que sur les mécanismes de notifications automatiques de ces mêmes providers, Snowpipe permet l’automatisation de l’ingestion des fichiers déposés. Aujourd’hui, Snowpipe est mis à profit par les utilisateurs Snowflake exprimant le besoin d’intégrer automatiquement et de manière performante de larges quantités de fichiers dans leur data warehouse.
Avantages du service Snowpipe
Là où traditionnellement, le chargement des données d’un data warehouse intervient en période creuse et en mode batch pour limiter la charge sur les systèmes sources et sur le data warehouse lui-même, Snowpipe offre une solution transparente et responsive pour les utilisateurs en quête de données fraiches, sans pour autant générer de la complexité ou demander de la maintenance.
Données fraîches
Snowpipe répond à des notifications générées par le cloud provider à l’arrivée de nouveaux fichiers. Il prend alors en charge les nouvelles données sans délai, et l’on peut retrouver et interagir avec les données dans Snowflake quelques secondes après l’apparition du fichier dans le cloud (S3 par exemple). Cette responsivité sans commune mesure avec le chargement par batch permet aux utilisateurs d’analyser et de consommer des données quand elles ont le plus de valeur.

Formats variés
Tous les types de données sont pris en charge, qu’ils soient semi-structurés comme JSON ou AVRO, ou qu’ils soient plats comme le CSV. Snowpipe est agnostique et se contentera de lire et d’ingérer le contenu du fichier dans une table.
Coûts maîtrisés
Les processus d’ingestion peuvent parfois être exécutés par les Tasks Snowflake. Celles-ci sont optimales pour un chargement de type batch par exemple, quand la fraicheur des données n’est pas la contrainte principale. Mais une Task nécessite un virtual warehouse (vWH) pour s’exécuter, et un vWH est facturé à la première minute, puis à la seconde. Ainsi, si survient la nécessité d’augmenter la fréquence d’exécution d’une Task durant 10 secondes, la facturation sera basée sur 60 secondes. A chaque exécution, c’est 50 secondes de compute qui sont payées alors que le vWH a fini son travail.
La facturation de la puissance de calcul de Snowpipe est différente. Sous le capot réside une utilisation plus efficiente des cœurs de processeur pour l’ingestion de fichiers. A cela s’ajoute une facturation à la seconde, dès la première seconde. Dans les faits, pour des processus d’ingestion similaires, Snowpipe sera 2x à 4x plus économe qu’une tâche exécutée par un Virtual Warehouse.
Maintenance… Quelle maintenance ?
Du provisioning de la puissance de calcul à la notification par le cloud provider, en passant par l’historique des fichiers déjà ingérés, Snowpipe est totalement autonome. Après la configuration initiale, le pipe est indépendant et ne nécessitera pas d’attention tant que la source des fichiers ne change pas, ou que la table d’ingestion reste la même.
Mise en place de Snowpipe
Avant toute chose, il convient de s’assurer que l’instance Snowflake est compatible avec la destination des fichiers que l’on souhaite ingérer automatiquement avec Snowpipe.

Tableau de compatibilité Snowpipe
On peut constater qu’à l’heure actuelle, seul un compte Snowflake hébergé sur AWS autorise un fonctionnement cross-Cloud de Snowpipe. Une instance Snowflake sur GCP ne pourra mettre en place Snowpipe que pour intégrer des fichiers provenant de Google Cloud Storage. On peut contourner cette limitation avec les appels REST API Snowpipe, grâce auxquels on peut s’affranchir des limitations cross-Cloud.
Pour illustrer la configuration de Snowpipe, nous prendrons ici l’exemple d’une intégration de fichiers en provenance d’un bucket S3. La mise en place se déroule à la fois sur AWS et sur Snowflake.
Configuration AWS
Snowflake a besoin des privilèges de lecture et de listing des fichiers dans le bucket où ils parviennent initialement.
La première étape consiste donc en la création, dans AWS, d’une stratégie pour Snowflake. Cette stratégie porte 4 privilèges sur le bucket:
s3:GetBucketLocation
s3:GetObjec
s3:GetObjectVersion
s3:ListBucket

Template de la stratégie AWS
Est ensuite créé sur AWS un rôle qui va bénéficier de cette stratégie : il sera dédié exclusivement à Snowflake, qui va l’utiliser dans une Storage Integration.
Du côté de Snowflake
L’identifiant unique du rôle AWS, son ARN, est un paramètre renseigné à la création d’une Storage Integration. Sur la base des permissions associées au rôle, Snowflake crée alors automatiquement un utilisateur AWS disposant lui aussi de son propre ARN ainsi que d’un ID externe.
Ces deux informations sont des attributs de la Storage Integration et permettent, de retour dans AWS, de modifier la relation de confiance du rôle créé pour Snowflake.
La liaison faite grâce à ce premier échange de bons procédés entre AWS et Snowflake, le champs est libre pour s’atteler à la création des autres objets dont nous avons besoin pour notre ingestion automatique dans Snowflake.
Le premier est un stage externe : il référence la localisation du bucket et éventuellement à quel sous-dossier s’intéresser, mais surtout grâce à quelle Storage Integration y accéder, car c’est avant tout cette dernière qui est garante des droits d’accès au bucket.
Le deuxième objet est une table d’ingestion. Une simple colonne VARIANT suffit dans le cas d’une intégration de fichiers JSON ou XML par exemple.
Le troisième objet est un FILE FORMAT qui saura lire le fichier
Ces trois objets prêts, il ne reste plus qu’à créer le Snowpipe. Sa définition est des plus simples :
CREATE PIPE MyPipe
AS COPY INTO MyTable
FROM @MyExternalStage FILE_FORMAT = MyFormat
C’est tout !
La dernière pièce du puzzle : la notification AWS
Notre pipe est prêt. Il n’attend qu’une chose : qu’AWS lui fasse signe qu’un fichier est arrivé sur son bucket.
Il faut pour cela mettre en place dans AWS une file de notification. Et là encore, Snowflake a déjà facilité le travail : à la création du Pipe, une notification_channel a été créée. On peut la voir en tant qu’attribut en exécutant la commande SHOW PIPES. L’ARN ainsi mis à disposition est donné à AWS lors du paramétrage de la notification dans AWS.
La création d’une nouvelle notification se fait dans AWS au niveau du bucket. Configurée pour déclencher un évènement à chaque création d’objet, elle envoie dans une file SQS les messages qui seront reçus par le Snowpipe. La file SQS existe déjà, c’est le pipe qui l’a créé à l’étape précédente : il ne reste plus qu’à en copier l’ARN dans les paramètres de la notification et le tour est joué.
Mis bout à bout, l’architecture de cette ingestion automatique est résumée par le schéma suivant :
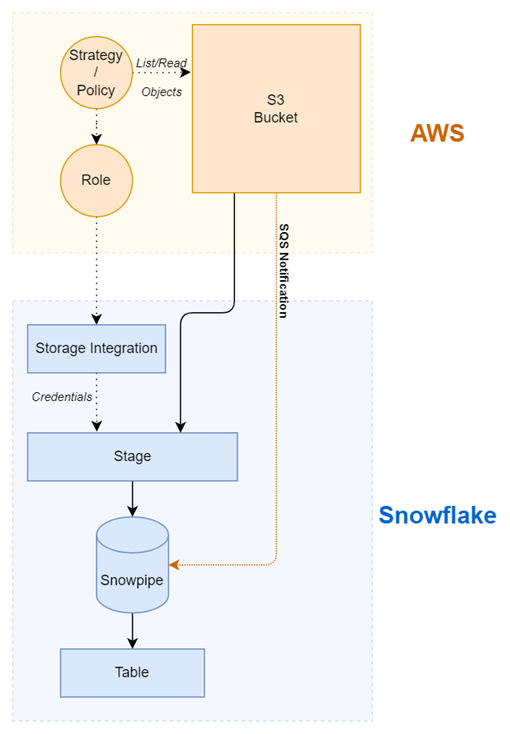
Pour finir
On voit rapidement ce qui fait tout l’attrait de Snowpipe dans les processus d’ingestion de fichiers. Sans réel désavantage par rapport à la Task, dès que se fait ressentir un besoin d’intégration rapide des nouvelles données parvenant dans un Cloud Storage, il est au contraire plus rapide, scalable à l’infini sans intervention humaine et plus économe à l’usage.
De la création de la stratégie AWS au premier fichier intégré, on peut configurer en quelques heures un ou plusieurs Snowpipes et commencer à tirer parti de l’incroyable puissance de ce service Snowflake.





