Episode 1
Azure Data Platform
Dans cette série d’articles je vais vous présenter les services « Data » proposés chez Azure et plus particulièrement ici Azure SQL Data Warehouse (ADW).
Azure est la plateforme cloud de Microsoft qui embarque un grand nombre de services et d’applications.
SQL Data Warehouse (ADW) est le service entrepôt de données dans le cloud Microsoft qui associe un stockage azure et un traitement parallèle de masse (Massively Parallel Processing).
SQL Data Warehouse est entièrement basé sur les dernières version SQL Server, la compatibilité et/ou la migration entre un environnement « On Prem » ou encore SQL Database vers ADW est donc optimale.
L’architecture d’ADW est basée sur des nœuds comme le représente le schéma ci-dessous
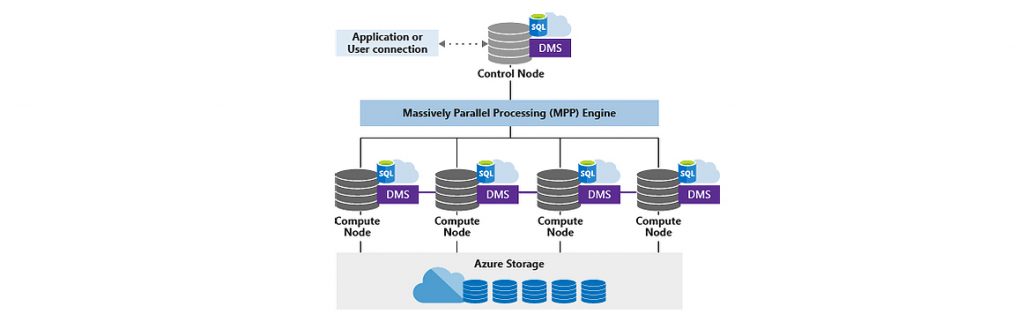
Les traitements peuvent être ainsi répartis sur plusieurs nœuds pour optimiser le plus possible les temps de traitement et proposer ainsi des temps de réponses excellents.
ADW a spécialement était conçu pour gérer de très grosse volumétrie de données. Pour des volumétries en dessous de 250 Go il est préférable d’utiliser un SQL Server « On Prem » ou Azure SQL Database (SQL Server Cloud) qui répondra certainement mieux aux contraintes budgétaires sans impacter les performances.
Traitement des requêtes
Nœud de contrôle : tour de contrôle du service ADW qui permet d’optimiser le traitement des requêtes et gérer les connexions au service
Nœud de calcul : chaque nœud contient une instance Azure SQL Database qui stockent les données et exécutent les requêtes. Les nœuds de calcul fournissent la puissance de calcul du service ADW.
Quand une requête est exécutée, le nœud de contrôle divise le travail en 60 requêtes plus petites qui s’exécutent en parallèle. Chacune de ces requêtes s’exécutent sur l’une des distributions de données.
ADW dispose de 60 distributions répartis par nœud en fonction du niveau choisi. Ce niveau de performance et donc de tarification est mesuré grâce au Data Warehouse Units (DWU pour GEN1) ou encore Compute Data Warehouse Units (cDWU pour GEN2).
La configuration minimale est composée d’un nœud de calcul qui inclus les 60 distributions, et la configuration maximale est composée de 60 nœuds de calcul contenant chacun 1 distribution. Gen 1 et Gen 2 correspondent au niveau de service et performance proposé pour ADW. Gen 2 est la dernière version d’architecture matériel et fournit 2,5 fois plus de mémoire par requête que Gen 1.
Paramètre de la capacité de l’entrepôt de données
Chargement et stockage des données :
Pour des performances optimales, le chargement des données dans ADW doit suivre le processus d’extraction, chargement et transformation (ELT) plutôt que l’extraction, la transformation et le chargement (ETL).
Concrètement il s’agit d’extraire ses données sources dans des fichiers texte délimités, de les charger dans ADW et ensuite d’appliquer les transformations qu’il nous faut.
Afin de limiter les effets de latence entre les environnements, il est conseillé de déposer les fichiers sources dans Azure Blob Storage ou Azure Data Lake. Une fois les fichiers déposés dans l’un de ces environnements, les données peuvent être chargées dans des tables externes du datawarehouse en utilisant Polybase.
Polybase apparu avec la version 2016 de SQL Server, permet d’interroger des sources de données du type Hadoop, Oracle, Sql Server, Mongo DB, Teradata ou encore Stockage Blob Azure en utilisant T-SQL
Une fois les données sources chargées dans les tables externe d’ADW il est tout à fait possible d’appliquer des transformations sur les données pour ensuite les charger dans les tables de production du datawarehouse.
Exemple de mise en œuvre d’un datawarehouse moderne :
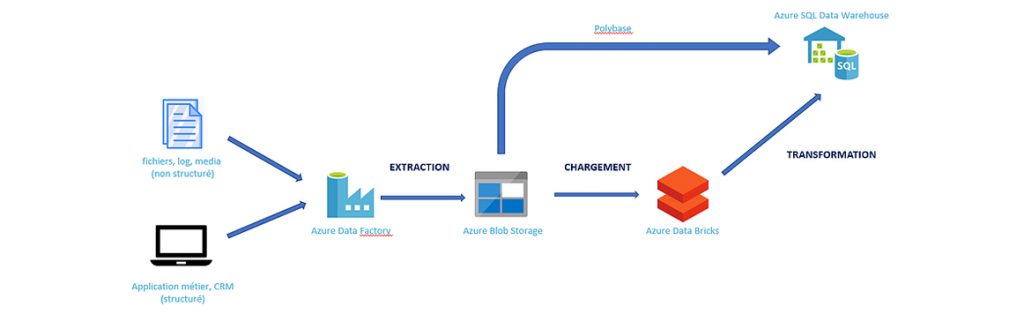
La facturation du stockage lié à ADW est totalement indépendante du calcul des requêtes. Ainsi on peut dimensionner la capacité de stockage indépendamment de la capacité de calcul, et la facturation se fait uniquement sur le service utilisé. C’est particulièrement utile et économique lorsque l’on souhaite mettre en pause le service de calcul quand il n’est pas utilisé.
Structure de la base de données ADW
Comme il s’agit d’un environnement MS Sql Server on va retrouver la majorité des fonctions d’une base relationnel classique. Cependant certaines fonctions ne sont pas disponibles, comme les clé étrangères, les clés primaires, les champs unique, les colonnes calculées …
Vous trouverez plus d’informations à ce sujet sur cette page : Fonctions de tables non supportées ADW propose les index suivants :
- Clustered
- Non Clustered
- Column Store
Par défaut si aucun index n’est spécifié au moment de la création de la table, ADW crée un index Column Store.
Les index uniques ne sont pas gérés dans ADW.
SQL Data Warehouse Microsoft documentation Data





